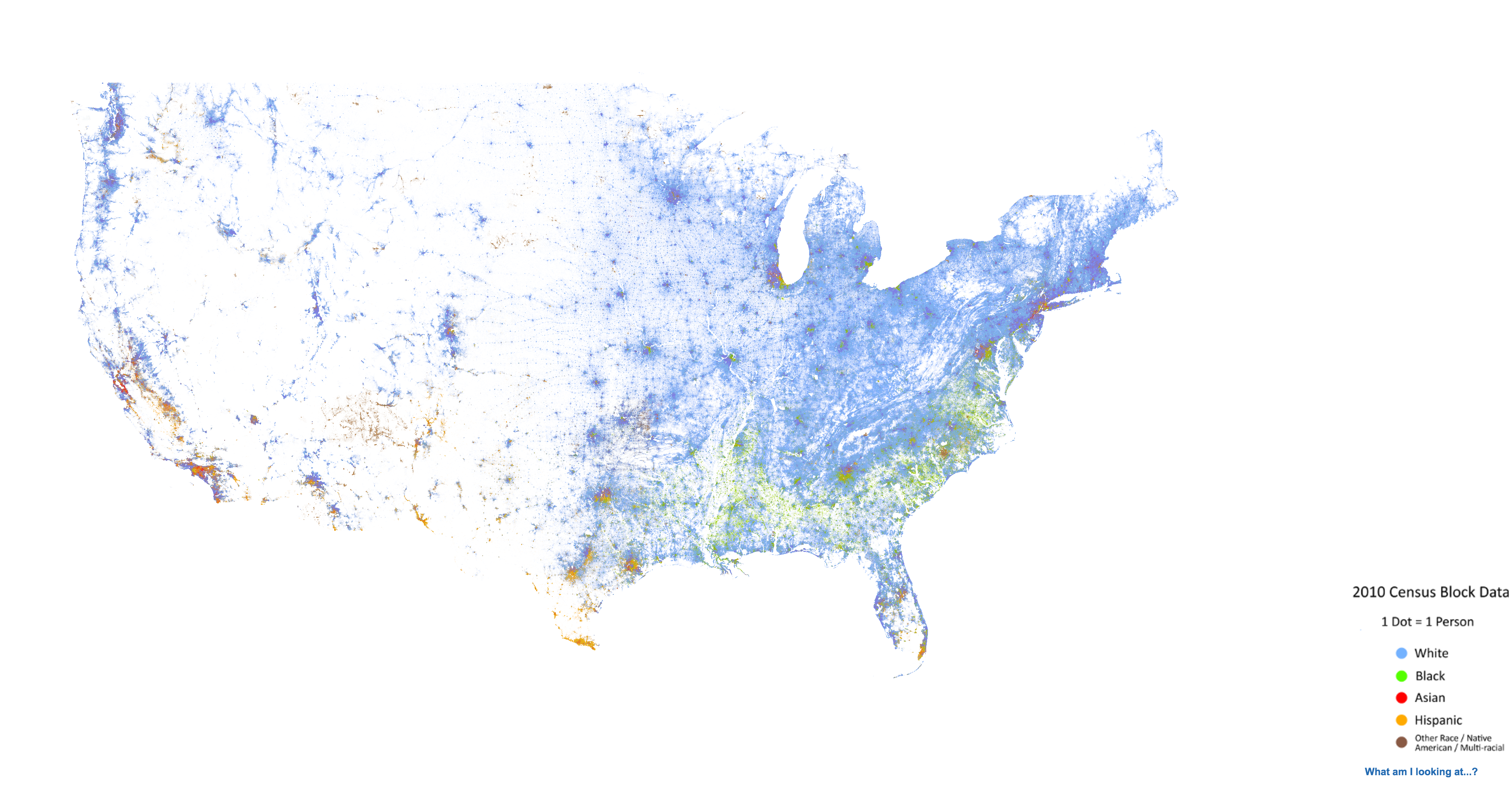
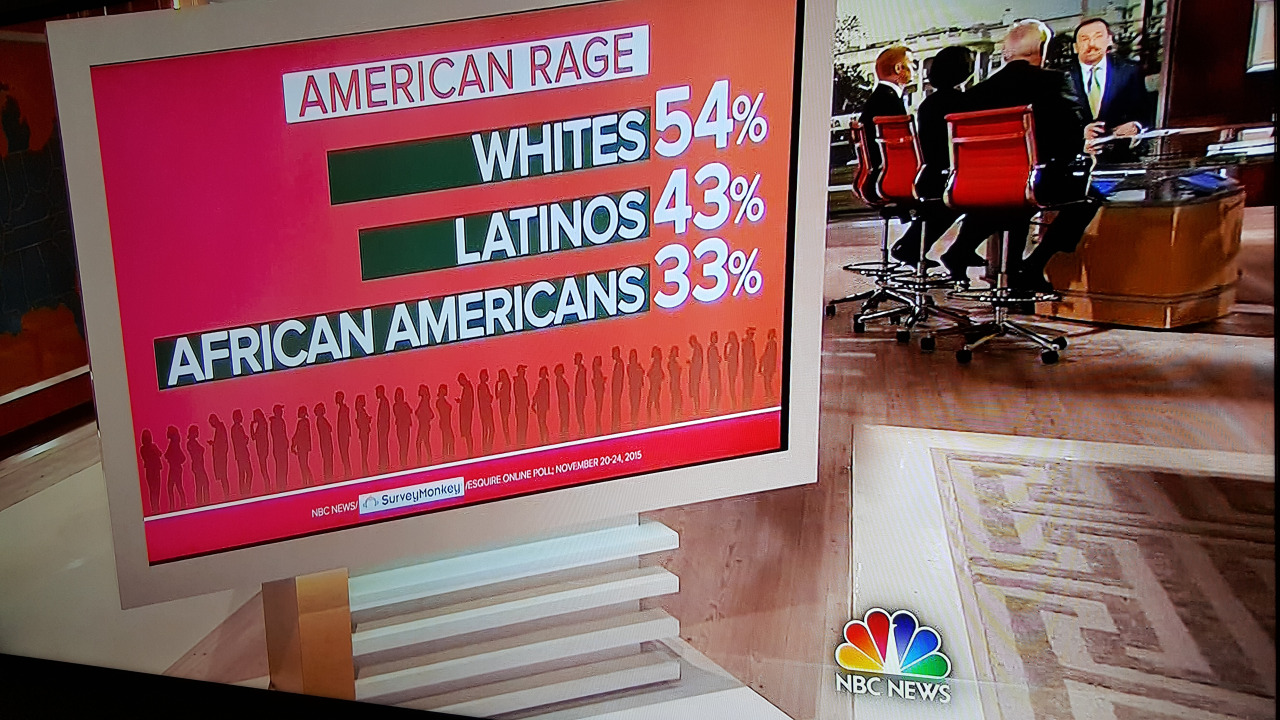
This is a required response on the assigned reading of in CS686.
After reading the preface I realized that this book is really worth reading, at least for someone like me that doesn’t have any former experience in Data Visualization.
Something About the Book
Before this book, if you want to learn Data Visualization you have basically two choices. First is you could dive right into academic papers, and as said by Alark, those papers assume you knows a lot in the field. So the learning curve becomes very steep although the things you read is really “fresh” and you know right away where the idea originates from (may not be useful but sometimes makes me feel its more trust-worthy). Another way is to read some book that’s related to Data Visualization, like some Computer Graphics books, which don’t really talk about Data Visualization systematically, or some other books that really focused on the foundation of Data Visualization (the “from bottom to top way” as described by Tamara Munzner).
Neither of the two ways of learning gives readers enough insights with which they can use immediately into the projects they care about. And that’s the reason for the VAD book. Which focuses on the patterns & frameworks that help readers make the right design decisions and, even more, with those higher level concepts in mind it would become easier to read those academic papers if the reader wants to dig further.
Something About Chapter 1
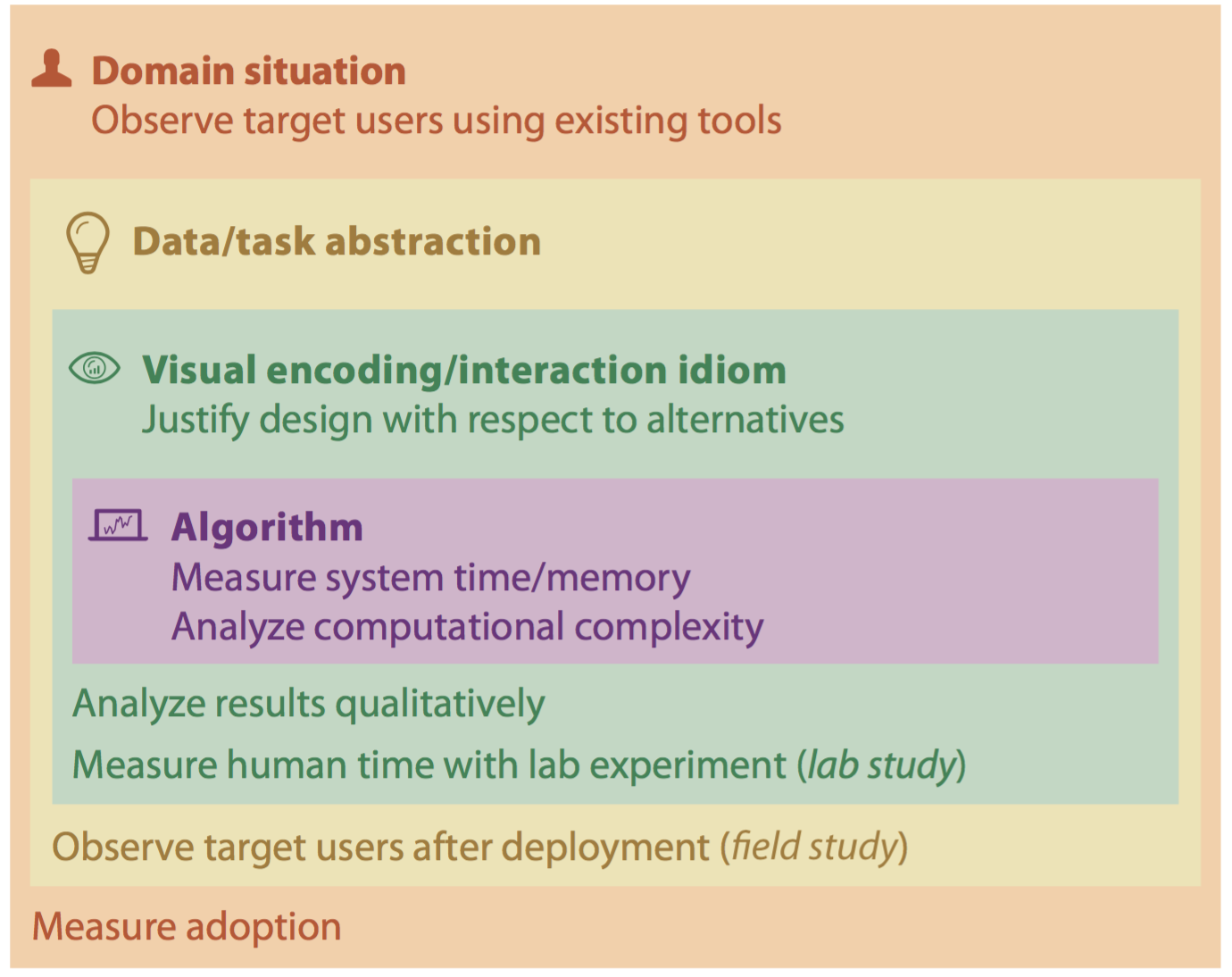
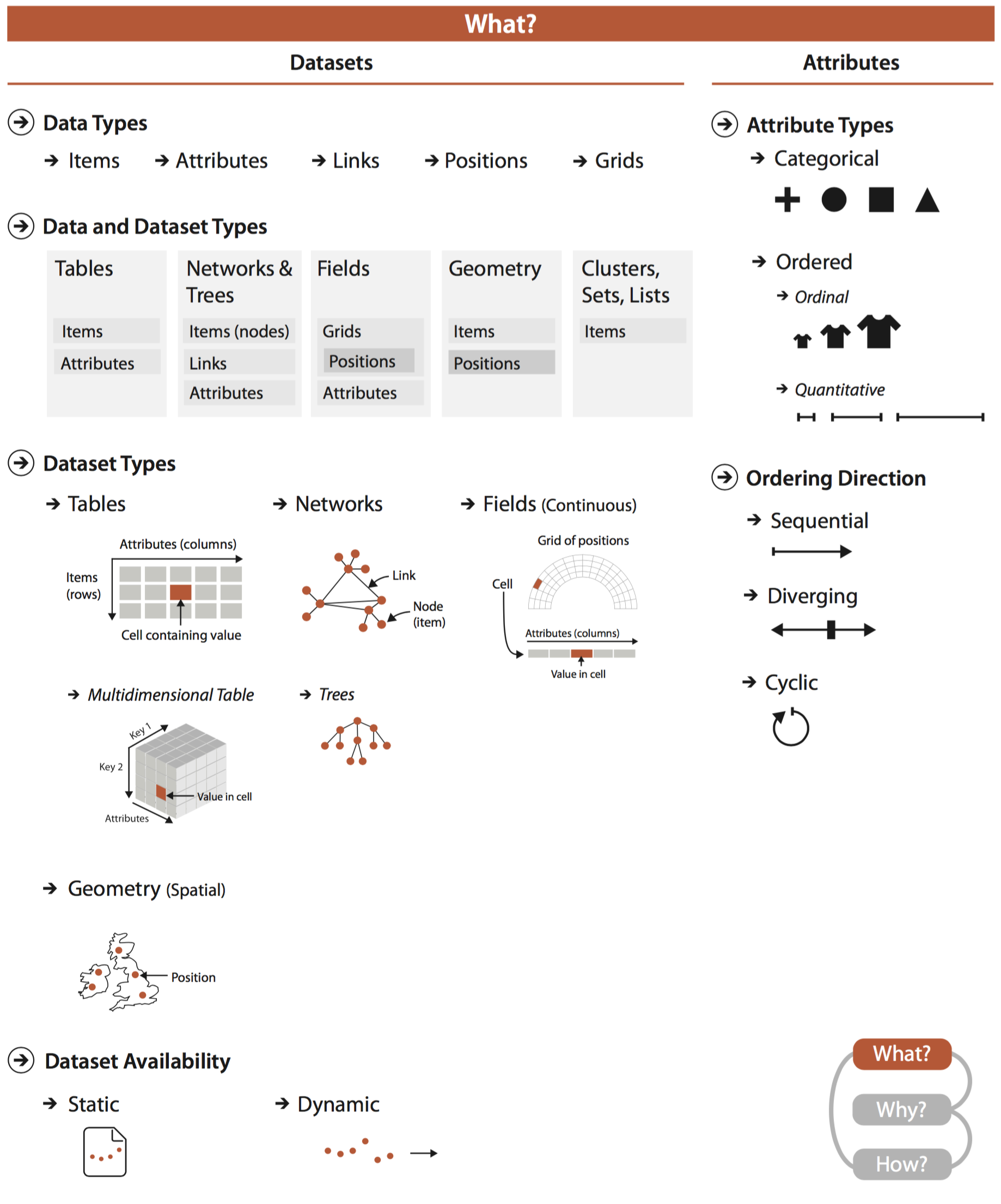
The first chapter of this book is really explaining what is Data Visualization. The author starts from a fairly abstract definition of “vis” (I will start to use this phrase from now on since it’s adopted by the author) and asking potential questions on the definition. Instead of writing a list that rephrases the things the author described in the chapter. I want to talk a little about something that really enlightened me.
In Chapter 1.2, when the author is trying to explain human’s role with the vis tool, she mentioned that the “many kinds of uses” of a vis tool which can be for both transitional use or for long-term use. This indeed opened up my mind about tooling in a large project, and possible usage of vis tools.
A simplest example is when we are writing a small project at school, most of the time we will print out debug information. Well, this is a primitive kind of visualization, which is not a “good” visualization simply because it doesn’t scale.
When the project gets larger, the time spent on tooling should grow respectively. And building a vis system sometimes is as important as implementing new features or even writing unit tests and integration tests. A great example is a monitoring system. It could be used not only for preventing regression introduced by adding new features or refactoring, but it sometimes can give out hidden patterns that will cause major crash. Just think of an unusual high I/O wait on your server, which sometimes is not sensible by your user but it could potentially hiding some defect in your HDD which will result in a total disaster in the near future.
With that said, a decent understanding in building good vis tools is very important not only for practitioners, but also for those who work in other fields that is related to complicated systems.